Data Extracts
An extract is a special kind of data table that is stored by Ultorg itself, on your local computer. It is populated from one or more associated source perspectives, and can be refreshed on demand. An Ultorg extract is analogous to a “materialized view” in SQL.
In the Folders sidebar, an extract is shown with the arrow-into-table icon (![]() ). Source perspective(s) (
). Source perspective(s) (![]() ) are displayed if the extract's icon is expanded. Status indications may be shown after the extract's name.
) are displayed if the extract's icon is expanded. Status indications may be shown after the extract's name.
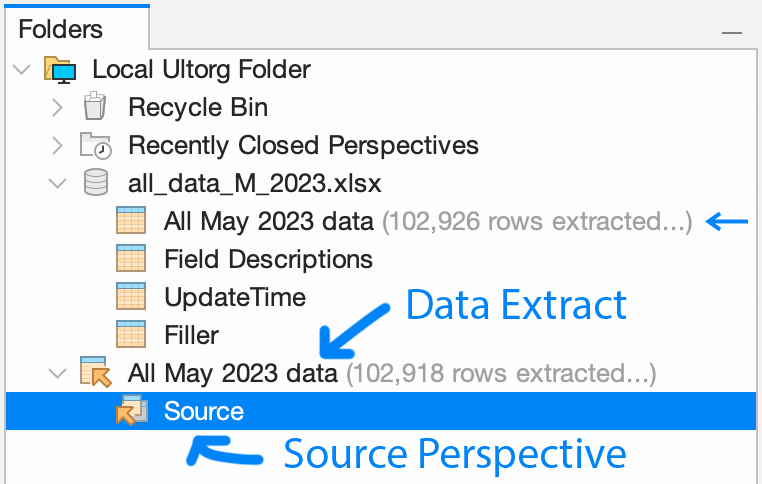
The screenshot above shows the Folders sidebar with an extract that copies data from a single source table. More complex source perspectives are permitted, defining any visual query.
Use Cases
Extracts can be used for various purposes:
- To store an offline copy of an external data table.
- To store a filtered-down subset of data from an external data table.
- To store the result of a long-running perspective query.
- To create a simplified view of the results of a complex perspective query.
- To combine (UNION) rows from data tables with a similar columns and data types.
- Automatically, for local query execution and queries over multiple data sources.
Generated Extracts
Most extracts are created automatically, for use with local query execution. For example, when you join tables from two different data sources, Ultorg creates an extract of both tables, and runs the query on your local computer. This happens behind the scenes, with no user input.
Automatically generated extracts can be found under Generated Extracts in the Folders sidebar.
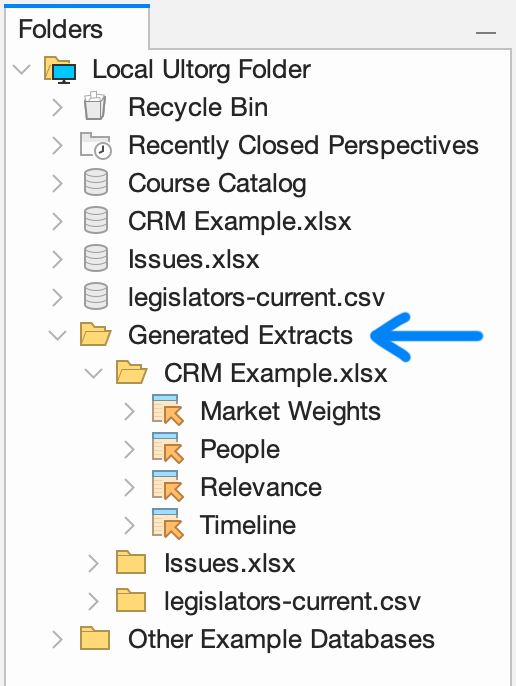
You can safely delete the Generated Extracts folder at any time, or any of the extracts inside it. Ultorg will re-generate extracts as needed.
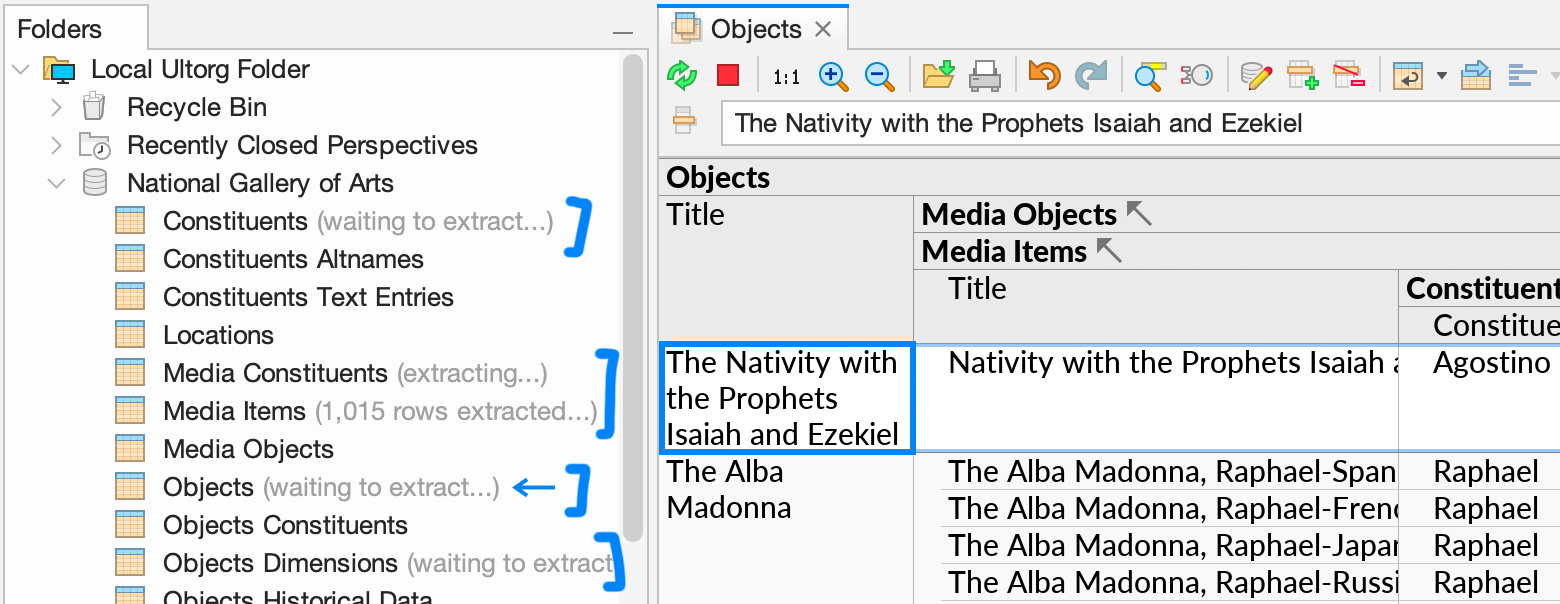
When an extract is being used as a substitute for an external data table, ongoing loading state will be shown in the Folders sidebar on both the extract and the original data table.
User-Defined Extracts
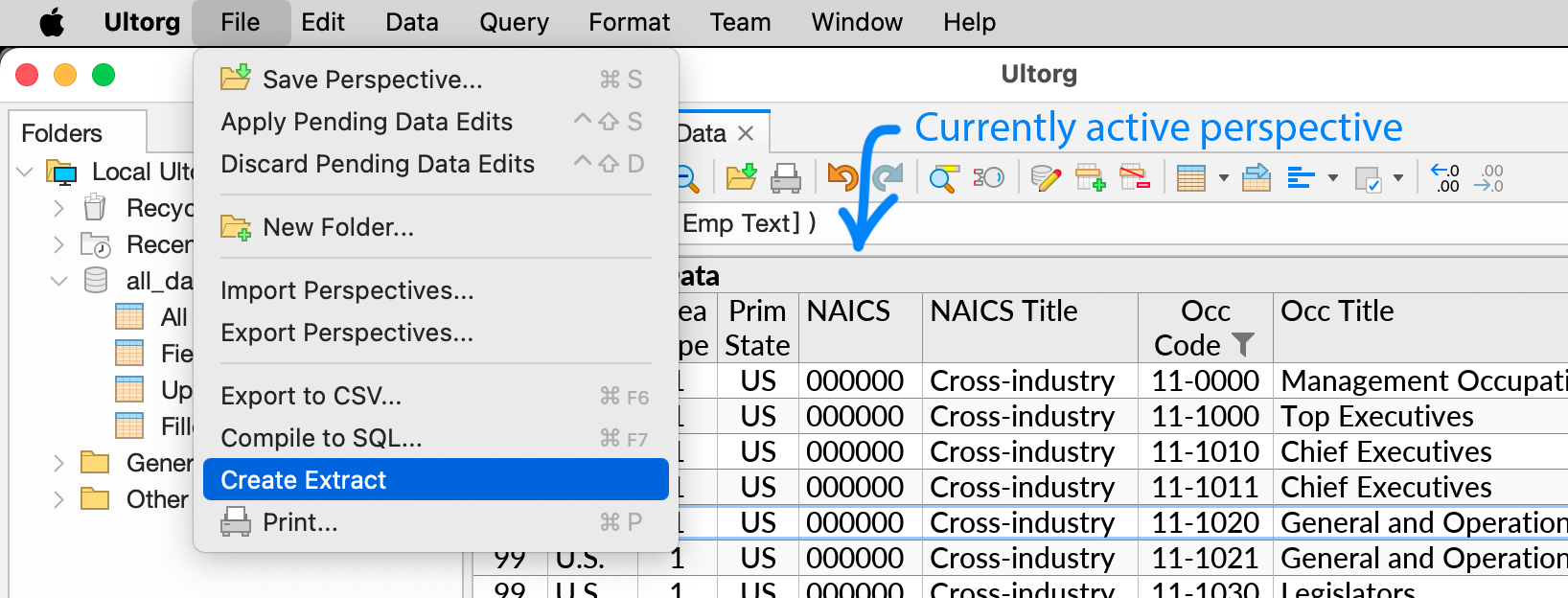
To create an extract from the currently active perspective, click Create Extract in the File menu. Alternatively, right-click a data table or saved perspective in the Folders sidebar and click Create Extract in the context menu. A new extract will appear in the sidebar.
Data from Subqueries
An extract stores flat, tabular data only, like a table in a relational database. Thus, when you create an extract from a perspective, only fields from the top (root) level subquery are included. Formulas can be included, and formulas may contain aggregate functions over subqueries.
Sorted-on and primary key fields in the root subquery are included even if originally hidden.
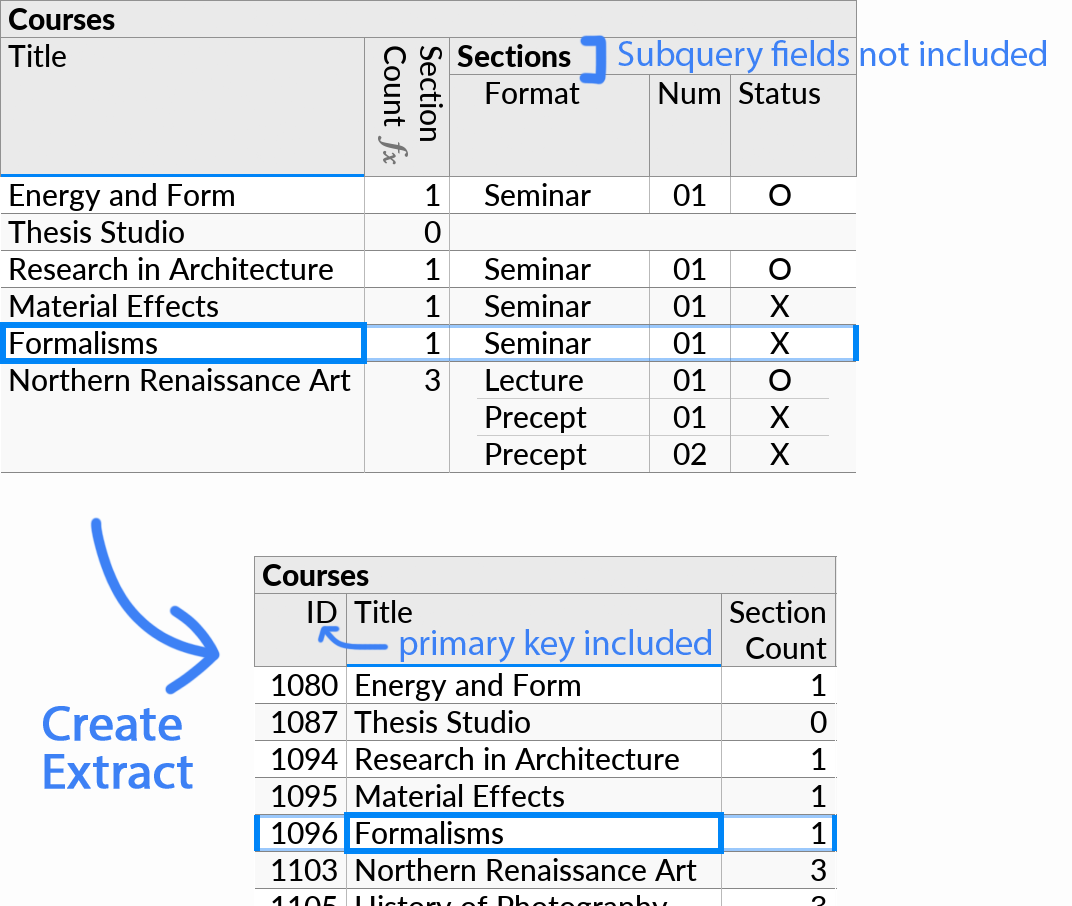
If you need an extract to include data from deeper subqueries, you can select the fields to include using multiple selection, and invoke Custom Group. If prompted, place the Custom Group at the topmost possible level.
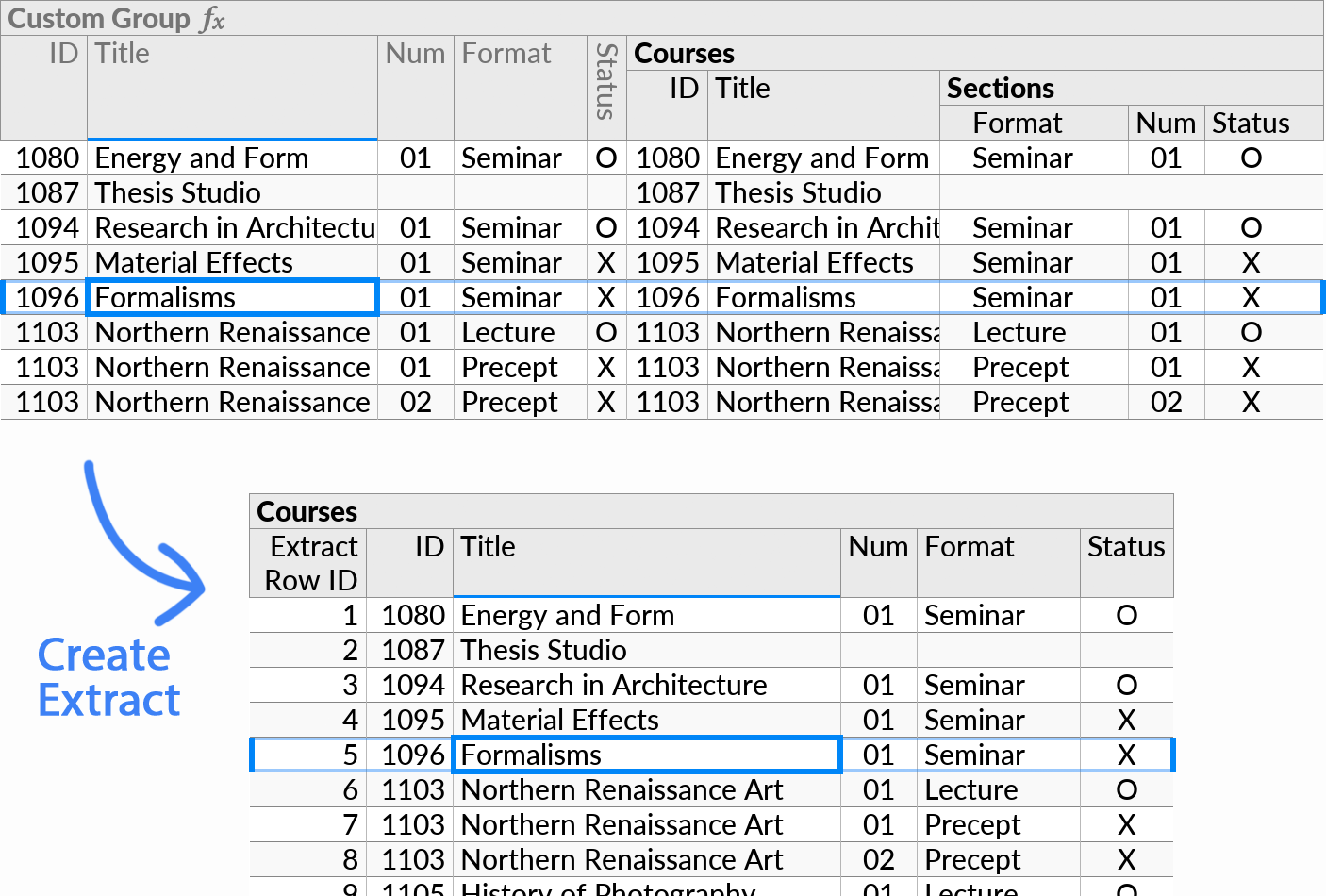
The effect here is equivalent to a JOIN operation in SQL, with values from the Courses table repeated for each corresponding row in the Sections table.
More precisely, the effect seen here is that of a left join, meaning that courses without a section (“Thesis Studio”) are listed once but with null values for fields in the Sections table. You can change this behavior with the Hide Parent If Empty setting on the Sections subquery.
UNIONed Extracts
If an extract has multiple source perspectives, then rows from each source perspective will be appended one after the other. This is similar to a UNION operation in SQL.
Most commonly, this feature is used to to create a single table from a dataset which may have been split up by year or other attributes. For example, a table with data from 2014 and a table with data from 2015 can be combined into a single extract that contains rows from both years:
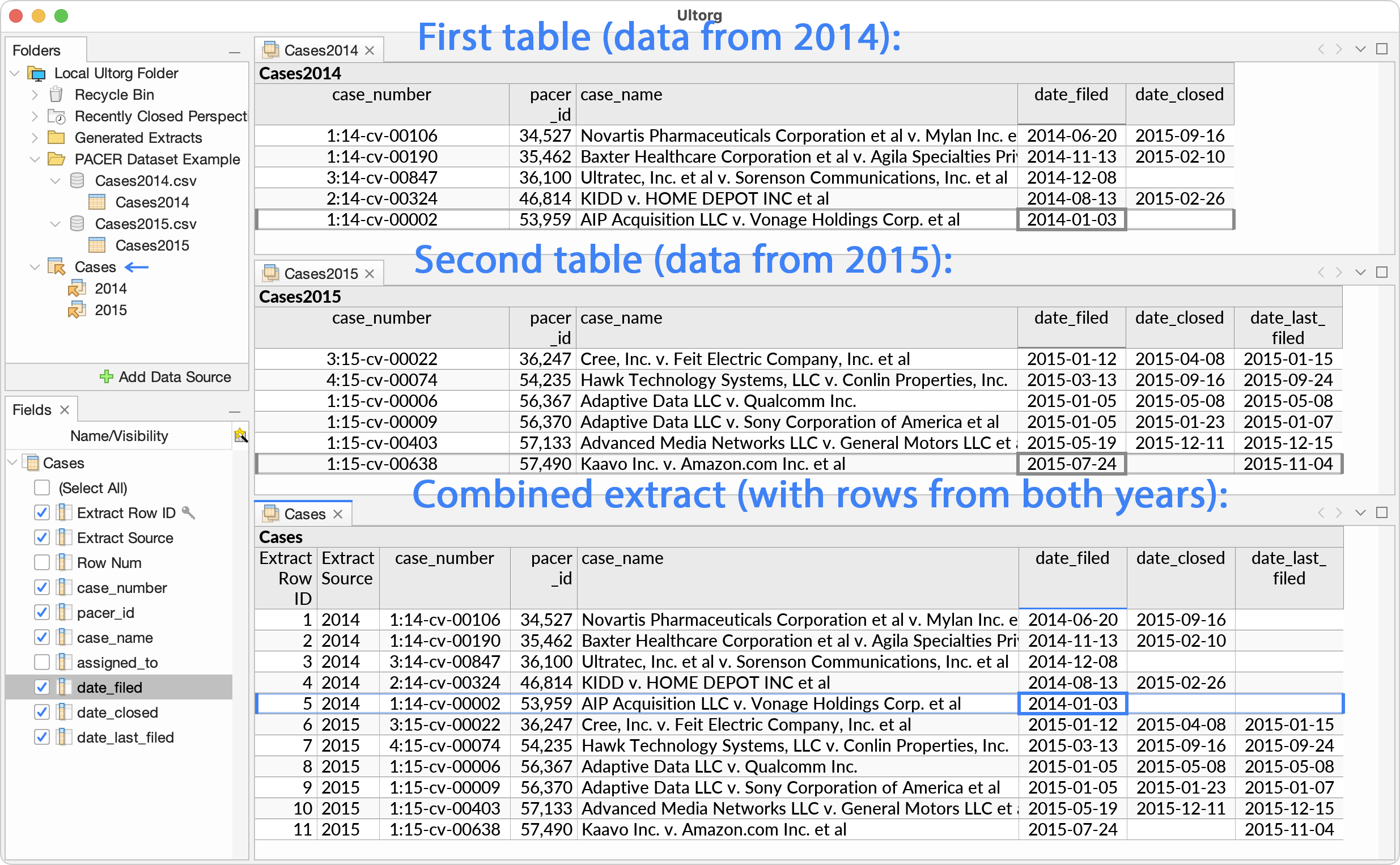
Fields in the different source perspectives are matched by name to map to different columns in the extract. For example, if two source perspectives both have a field named “Country”, then they will both map to a single “Country” column in the extract.
If a source perspective has no mapped field for a given destination column, a null value is used for that column during extract loading. See the “date_last_filed” column in the example above.
During extract loading, source perspectives are processed in alphabetical order by name, as displayed in the Folders sidebar. An Extract Source column is automatically added to hold the name of the source perspective for each set of loaded rows. See the example above.
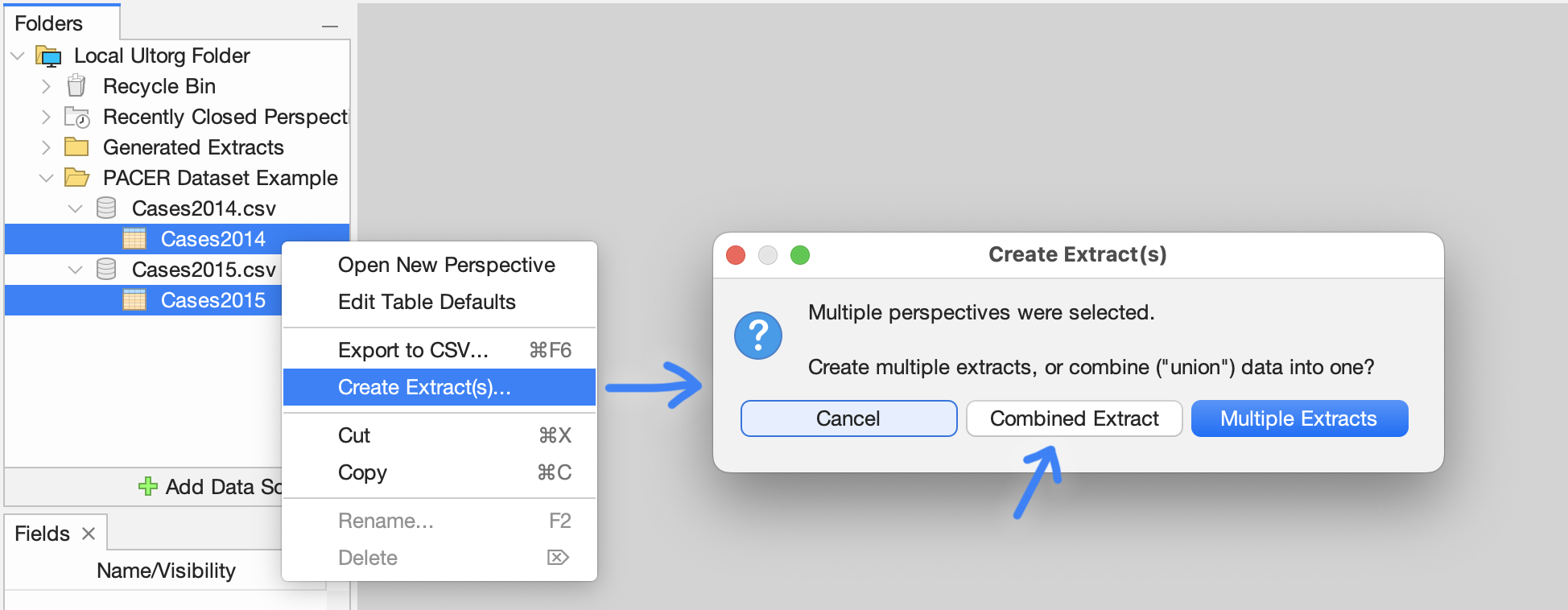
To create an extract with multiple source perspectives, right-click a selection of multiple tables or perspectives in the Folders sidebar, and click Create Extract(s). Then click Combined Extract in the dialog box that appears.
Primary Key Columns
An extract, like other data tables, may designate a subset of columns as its primary key. Primary key columns hold identifying values for each row.
An extract created from a single data table will reuse the source table's primary key if possible. Extracts from multiple tables, or from a table without a primary key, will use a generated primary key column called Extract Row ID.
Use in Query Execution
User-generated extracts, like generated ones, may be used to facilitate local query execution. Ultorg will detect any extract that map to an external data table, and use it when appropriate. For more details, see Local Query Execution.
Refreshing Extracts
An open perspective can be refreshed with the Refresh Data (![]() , Ctrl+R/⌘R) action. If local query execution is enabled or required for the perspective, the underlying extracts will be automatically refreshed as well.
, Ctrl+R/⌘R) action. If local query execution is enabled or required for the perspective, the underlying extracts will be automatically refreshed as well.
You can manually refresh a specific extract by right-clicking it in the Folders sidebar and clicking Refresh Extract Data.
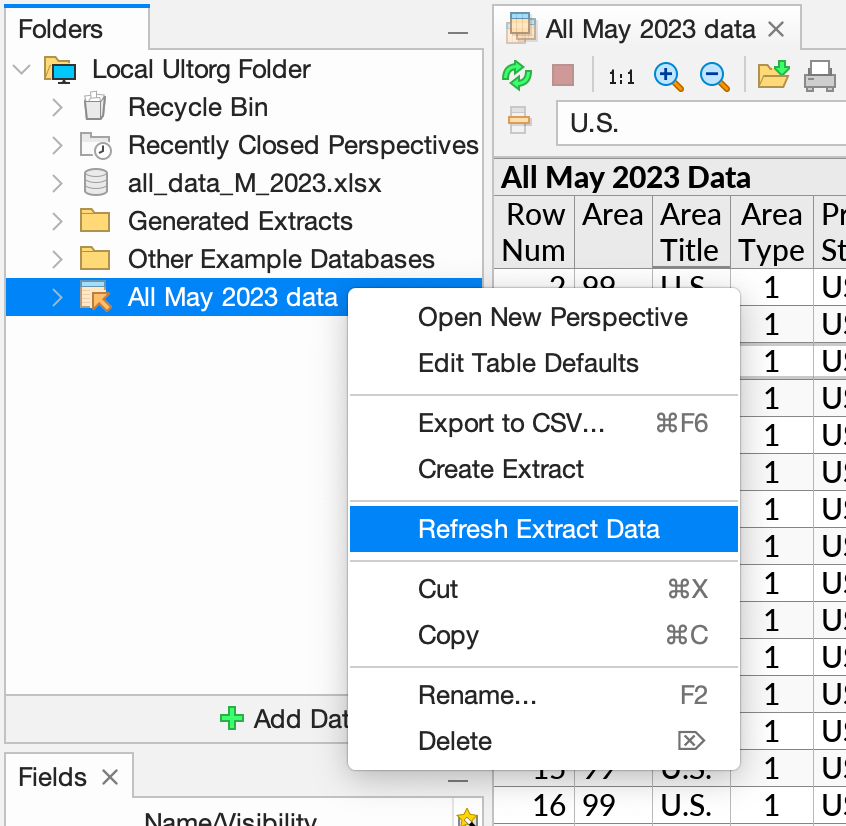
A long-running extract loading process can be canceled with the Cancel Extract Loading action that appears in the same context menu.