Performance Tips
Ultorg perspectives can be used to express arbitrary database queries—including slow ones! This page contains tips for dealing with large datasets and long-running queries.
Users are also welcome to contact us with questions specific to their data source.
Ultorg's Architecture
Ultorg's direct manipulation interface stays responsive through three architectural principles:
- Query execution is handled by an external database engine. Visual queries are compiled to SQL and executed in a separate process, either remotely or on your local computer.
- The user interface loads only as much data is needed for display.
- The user interface continues to work even as queries have yet to return with results.
Because long-running operations will not block the user interface, you can build queries interactively even on large databases, without waiting for each intermediate result.
Slow Table List Retrieval
When you first connect to a relational database, Ultorg will retrieve a list of available tables. This should normally be a fast operation.

If loading the table list takes a long time, consider checking the log messages at Help→Diagnostics→Application Log. In some cases the connected user may have access to an unnecessarily large number of database catalogs.
Slow Queries
If you encounter a slow database query, first check that a “trivial” query on the same data source, such as viewing the contents of a single data table, works as expected. Otherwise, a poor network connection may be to blame. You can disconnect and try again.
Solutions in Ultorg
As when typing SQL directly, there are often many ways to express the same query as an Ultorg perspective. If a particular visual query is slow, try hiding some fields, or adding some filters.
One common technique is to add a filter to reduce the amount of data while constructing and experimenting with a query. Once you are satisfied with the overall query, you can clear the original filter to get a more complete result.
Other tips:
- Sorting on an aggregate formula will tend to force the entire dataset to be processed. Showing both the sorted aggregate and its input rows may sometimes be slow. Hiding the subquery that shows the input rows will often make such queries faster.
- The Local Query Execution option may be faster than executing queries on a remote database. This is often true on fast, modern laptops.
Tuning the Database
Relational databases can be tuned in several ways, by the administrator of the database server. In particular:
- Make sure that each table has an explicit primary key defined, if possible. Tables with a primary key will perfom better in many Ultorg queries.
- For large tables, you can try adding indexes (CREATE INDEX in SQL) to table columns that are frequently used in joins or filters. This will often speed up relevant Ultorg queries.
Note that PostgreSQL, as an example, does not automatically create indexes on foreign key columns, even though such indexes are frequently useful.
Retrieve More Rows
When working with a perspective, Ultorg will normally limit the number of rows retrieved, and increase the limit only if you scroll to the bottom of the currently displayed result.
This behavior can be overridden, by opening the Format popup on the root label of the displayed result (the topmost bold heading) and setting the Retrieved Row Count option:
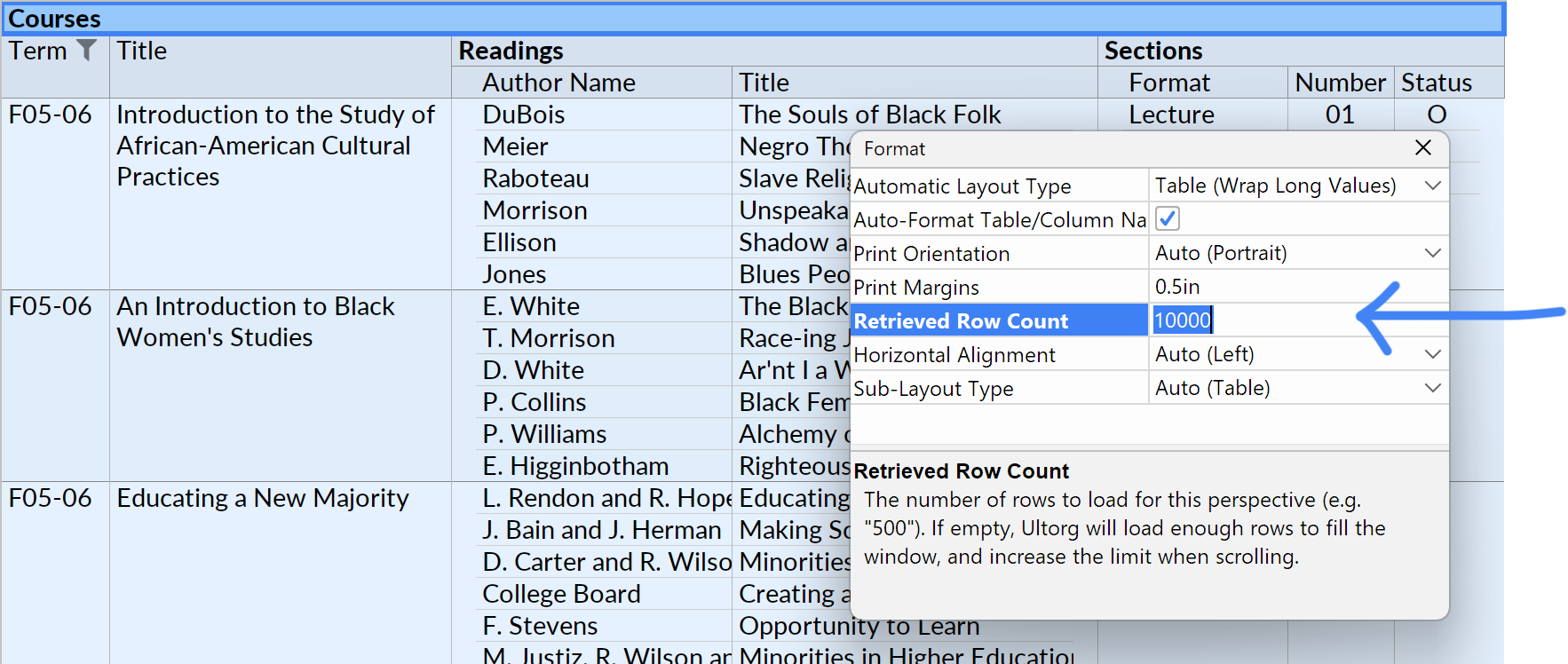
Retrieving a large number of rows may slow down query interactions, but may be useful for long-running queries. If you have a long-running query that returns a flat table of results, you may consider using the Create Extract feature to create a snapshot of the result instead.