Text Files (CSV/TSV)
Text Files (CSV/TSV)
Many tools will export data in the comma-separated values (CSV) format, or one of its variants. A CSV file encodes a single table of data as plain text, using line breaks to separate rows and commas to separate columns, as in the following example:
CustomerID,Date,Type,Duration 2,2023-01-29,Video Call,45 6,2023-03-27,Video Call,50 3,2023-04-12,Meeting,60 12,2024-05-21,Meeting,30
Other column delimiters are common as well, such as tab characters (tab-separated values/TSV) or semicolons. Additionally, a quote character (text qualifier in Excel) may be used to safely encode values that happen to contain one of the delimiter characters, or the quote character itself. See RFC 4180 for boring details.
Connecting
To connect to a CSV, TSV, or similar text file in Ultorg, click Add Data Source→Connect to File and select your file. The file name must have the extension csv, tsv, or txt.
You can also drag multiple files at once from your operating system's file explorer to the Folders sidebar in Ultorg.
After picking a file and confirming settings, your new data source (![]() ) will appear in the Folders sidebar with a single data table (
) will appear in the Folders sidebar with a single data table (![]() ) underneath:
) underneath:
Parse Settings
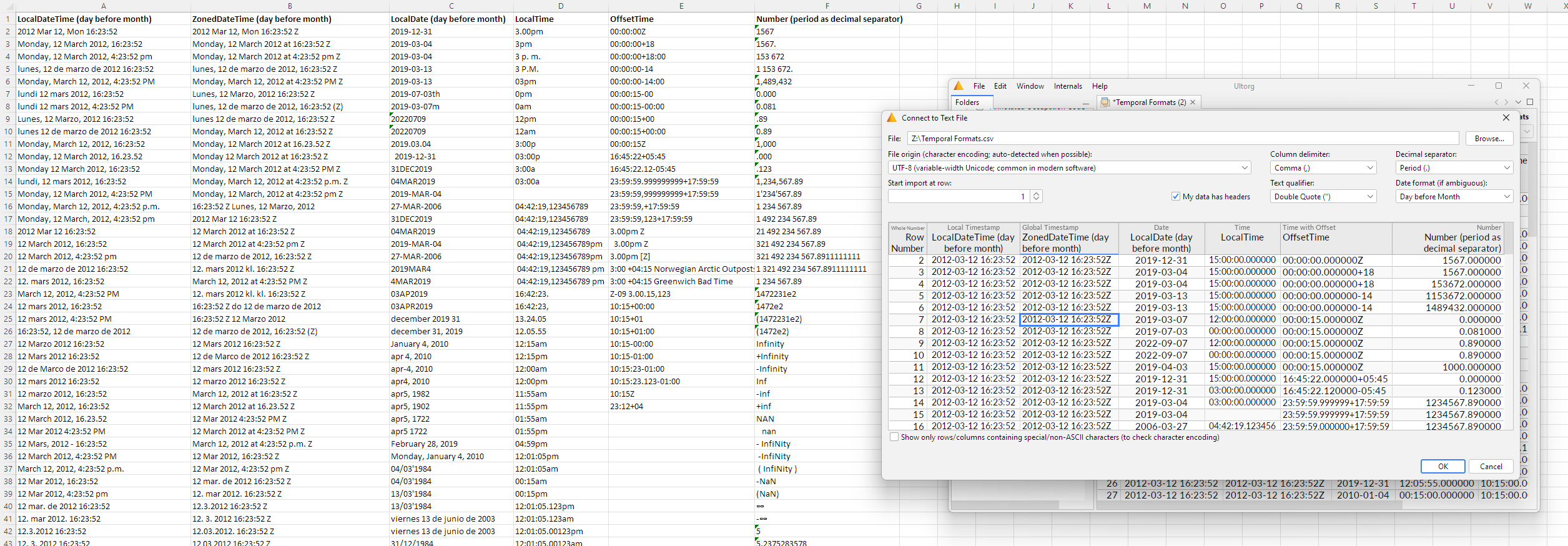
After picking your file, Ultorg will show a preview of the data and settings to use while parsing:
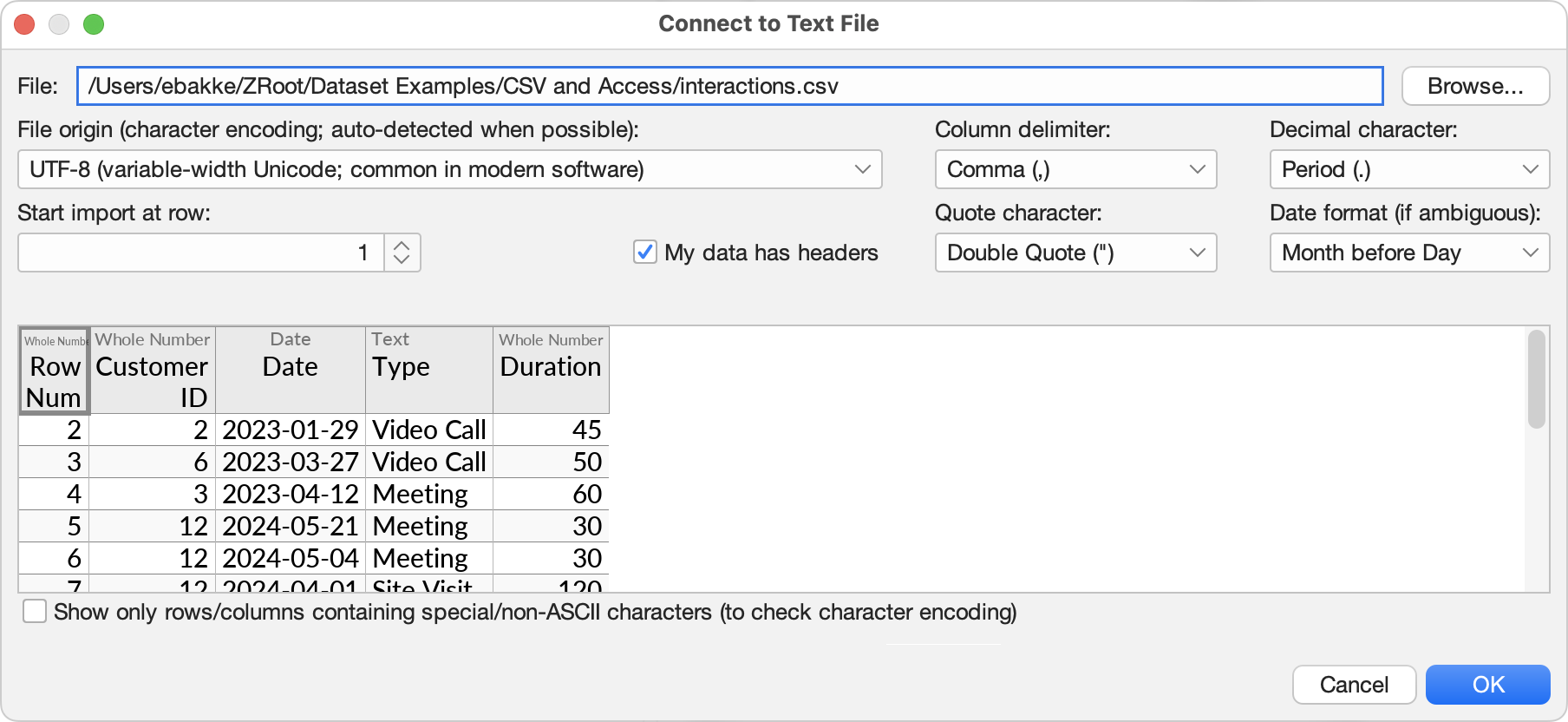
Auto-detected settings will be suggested initially. Depending on the contents of your file, these may not always be accurate. You should check the preview of your data to verify that each setting is correct, and make adjustments if necessary. The settings are as follows:
- File: The path to the file that is being parsed. You can edit this if the file has moved.
- File origin (character encoding): The character encoding that was used by the software that generated the file.
The character encoding defines the mapping of characters other than basic US English letters and punctuation. The list in the dropdown menu starts with the most common US and western European encodings. For auto-detection, Ultorg will make an educated guess among these, based on the presence and frequency of different characters in your file.
For data exported on Linux and MacOS, UTF-8 is the most common encoding. On Windows, however, language-dependent encodings from the 1990s, such as windows-1252 and IBM437, are still the default in many cases.
By checking Show only rows/columns containing special/non-ASCII characters, you can see if your data has special characters in it, and verify that they appear correctly. For English text, problems tend to occur around Microsoft Office “smart quotes” and other typographic characters.
In some cases, character encoding errors may have been stored in the actual raw data, at an earlier stage in the data processing pipeline. Such errors may still be visible, even if the character encoding is set correctly here.
- Column delimiter: The character between each value in a row.
- Quote character: A character that can be used to mark the beginning and the end of a value, for cases where the value itself contains line breaks or the column delimiter character. Double quotes (") are often used for this purpose. The quote character itself can be included in the value by doubling it. For example, William "Bill" Gates can be encoded as "William ""Bill"" Gates".
The C-style strings option assumes an alternative quoting strategy, where special characters are encoded with backslash escape sequences. All of the sequences from the JSON specification are supported. Surrounding double quotes will be removed if present, but are not mandatory; backslash escape sequences are processed in either case.
- Decimal character: For numbers, this setting determines whether a period or a comma is assumed as a decimal separator, e.g. 3.14 vs. 3,14. The US and UK uses period, while files from many other countries use comma.
The option not chosen here may, in some formats, be used as a thousands grouping character (e.g. 10,423,294.71 in the US). Other formats may use whitespace for this purpose (e.g. 10 423 294,71 in France). Ultorg accepts these formats.
Auto-detection of this setting will succeed if there exists numbers in the file that unambiguously reveals the correct decimal character (e.g. 3,14, though not 3,141).
Negative numbers may be indicated with a leading or trailing minus, or with brackets. E.g. -321, 321-, or (321).
- Date format: The day/month order to assume when parsing dates such as 2/3/2024 (which could mean either March 2 or February 3). See Date and Time Parsing below.
For auto-detection, Ultorg will assume that a consistent day/month order is used throughout the file, and look for values that reveal the format. For example, in 2/15/2022, the order must be Month-before-Day, since 15 is not a valid month.
ISO formats (YYYY-MM-DD) are always parsed as such, regardless of this setting.
- Start import at row: This setting allows you to skip lines in your file that may exist prior to the tabular portion of the data. No lines are skipped by default.
- My data has headers: This setting should be checked if the first row of your table contains column names. Auto-detected when possible.
Auto-detection of settings is done only when the Connect to Text File window is open, after a new file is selected. Once you have saved the settings, they will stay constant.
Data Types
Ultorg will auto-detect the data type for each column: Date, Time, Time with Offset, Local Timestamp (date+time), Global Timestamp (date+time+offset), Number, UUID, or Text. The detected data types are shown in the table header of the data preview:

If a column is detected as Text rather than another type that you expected, it is likely because at least one value exists that is not parseable to the expected type. For instance, a column that contains a mix of text and numbers will be assigned the Text type. You can still extract numeric values using a formula with the the num function.
Data type detection is done based on the first 7500 rows in the file. Subsequent values that do not conform to their column's type will be replaced with null values.
Some CSV or TSV exporters handle quoting incorrectly. Ultorg's parser will attempt to recover from such errors, and continues parsing even where errors are detected.
Date and Time Parsing
Text file sources support a wide range of date, time, and timestamp formats.
- For dates, explicit day/month names (e.g. "Mon, January 4, 2010") are recognized in English, French, German, Portuguese, and Spanish.
- Years in dates must have four digits.
- Various separator styles and field orders are accepted (e.g. "16:42:23,123", "2019MAR04", "25 March 2022 at 16:23:52", "Tue, 3 Jun 2008 11:05:30 GMT", "05.06.07 03.04.1955", "3p.m.").
- Various formats for time zone offsets and UTC/GMT/Z specifiers are supported. Non-UTC time zones require an explicit offset (e.g. "12/03/2011 10:15:30 +01 Europe/Paris").
- ISO 8601 formats are always parsed as such (e.g. "2022-07-28T02:12:20Z").
- Unrecognized or out-of-range values (e.g. "30.02.1999", "23:60") are always rejected. Weekday names, if present, are used for validation.
- All-midnight timestamp columns are detected as a simple Date column.